
Build a personalized avatar with generative AI using Amazon SageMaker
Generative AI has become a common tool for enhancing and accelerating the creative process across various industries, including entertainment, advertising, and graphic design. It enables more personalized experiences for audiences and improves the overall quality of the final products.
One significant benefit of generative AI is creating unique and personalized experiences for users. For example, generative AI is used by streaming services to generate personalized movie titles and visuals to increase viewer engagement and build visuals for titles based on a user’s viewing history and preferences. The system then generates thousands of variations of a title’s artwork and tests them to determine which version most attracts the user’s attention. In some cases, personalized artwork for TV series significantly increased clickthrough rates and view rates as compared to shows without personalized artwork.
In this post, we demonstrate how you can use generative AI models like Stable Diffusion to build a personalized avatar solution on Amazon SageMaker and save inference cost with multi-model endpoints (MMEs) at the same time. The solution demonstrates how, by uploading 10–12 images of yourself, you can fine-tune a personalized model that can then generate avatars based on any text prompt, as shown in the following screenshots. Although this example generates personalized avatars, you can apply the technique to any creative art generation by fine-tuning on specific objects or styles.
 |
Solution overview
The following architecture diagram outlines the end-to-end solution for our avatar generator.
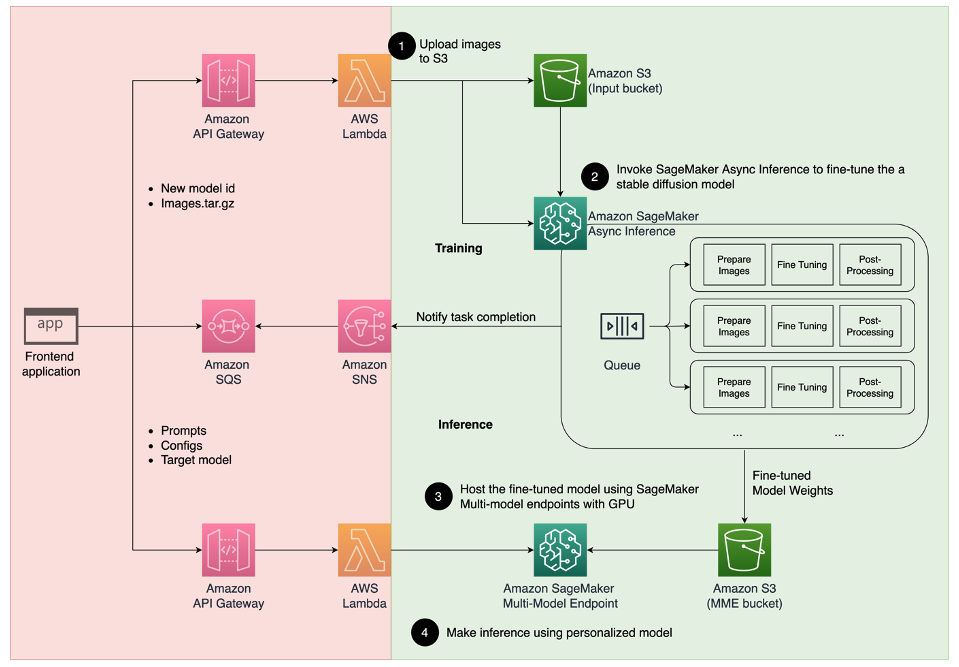
The scope of this post and the example GitHub code we provide focus only on the model training and inference orchestration (the green section in the preceding diagram). You can reference the full solution architecture and build on top of the example we provide.
Model training and inference can be broken down into four steps:
- Upload images to Amazon Simple Storage Service (Amazon S3). In this step, we ask you to provide a minimum of 10 high-resolution images of yourself. The more images, the better the result, but the longer it will take to train.
- Fine-tune a Stable Diffusion 2.1 base model using SageMaker asynchronous inference. We explain the rationale for using an inference endpoint for training later in this post. The fine-tuning process starts with preparing the images, including face cropping, background variation, and resizing for the model. Then we use Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning technique for large language models (LLMs), to fine-tune the model. Finally, in postprocessing, we package the fine-tuned LoRA weights with the inference script and configuration files (tar.gz) and upload them to an S3 bucket location for SageMaker MMEs.
- Host the fine-tuned models using SageMaker MMEs with GPU. SageMaker will dynamically load and cache the model from the Amazon S3 location based on the inference traffic to each model.
- Use the fine-tuned model for inference. After the Amazon Simple Notification Service (Amazon SNS) notification indicating the fine-tuning is sent, you can immediately use that model by supplying a
target_modelparameter when invoking the MME to create your avatar.
We explain each step in more detail in the following sections and walk through some of the sample code snippets.
Prepare the images
To achieve the best results from fine-tuning Stable Diffusion to generate images of yourself, you typically need to provide a large quantity and variety of photos of yourself from different angles, with different expressions, and in different backgrounds. However, with our implementation, you can now achieve a high-quality result with as few as 10 input images. We have also added automated preprocessing to extract your face from each photo. All you need is to capture the essence of how you look clearly from multiple perspectives. Include a front-facing photo, a profile shot from each side, and photos from angles in between. You should also include photos with different facial expressions like smiling, frowning, and a neutral expression. Having a mix of expressions will allow the model to better reproduce your unique facial features. The input images dictate the quality of avatar you can generate. To make sure this is done properly, we recommend an intuitive front-end UI experience to guide the user through the image capture and upload process.
The following are example selfie images at different angles with different facial expressions.

Fine-tune a Stable Diffusion model
After the images are uploaded to Amazon S3, we can invoke the SageMaker asynchronous inference endpoint to start our training process. Asynchronous endpoints are intended for inference use cases with large payloads (up to 1 GB) and long processing times (up to 1 hour). It also provides a built-in queuing mechanism for queuing up requests, and a task completion notification mechanism via Amazon SNS, in addition to other native features of SageMaker hosting such as auto scaling.
Even though fine-tuning is not an inference use case, we chose to utilize it here in lieu of SageMaker training jobs due to its built-in queuing and notification mechanisms and managed auto scaling, including the ability to scale down to 0 instances when the service is not in use. This allows us to easily scale the fine-tuning service to a large number of concurrent users and eliminates the need to implement and manage the additional components. However, it does come with the drawback of the 1 GB payload and 1 hour maximum processing time. In our testing, we found that 20 minutes is sufficient time to get reasonably good results with roughly 10 input images on an ml.g5.2xlarge instance. However, SageMaker training would be the recommended approach for larger-scale fine-tuning jobs.
To host the asynchronous endpoint, we must complete several steps. The first is to define our model server. For this post, we use the Large Model Inference Container (LMI). LMI is powered by DJL Serving, which is a high-performance, programming language-agnostic model serving solution. We chose this option because the SageMaker managed inference container already has many of the training libraries we need, such as Hugging Face Diffusers and Accelerate. This greatly reduces the amount of work required to customize the container for our fine-tuning job.
The following code snippet shows the version of the LMI container we used in our example:
In addition to that, we need to have a serving.properties file that configures the serving properties, including the inference engine to use, the location of the model artifact, and dynamic batching. Lastly, we must have a model.py file that loads the model into the inference engine and prepares the data input and output from the model. In our example, we use the model.py file to spin up the fine-tuning job, which we explain in greater detail in a later section. Both the serving.properties and model.py files are provided in the training_service folder.
The next step after defining our model server is to create an endpoint configuration that defines how our asynchronous inference will be served. For our example, we are just defining the maximum concurrent invocation limit and the output S3 location. With the ml.g5.2xlarge instance, we have found that we are able to fine-tune up to two models concurrently without encountering an out-of-memory (OOM) exception, and therefore we set max_concurrent_invocations_per_instance to 2. This number may need to be adjusted if we’re using a different set of tuning parameters or a smaller instance type. We recommend setting this to 1 initially and monitoring the GPU memory utilization in Amazon CloudWatch.
Finally, we create a SageMaker model that packages the container information, model files, and AWS Identity and Access Management (IAM) role into a single object. The model is deployed using the endpoint configuration we defined earlier:
When the endpoint is ready, we use the following sample code to invoke the asynchronous endpoint and start the fine-tuning process:
For more details about LMI on SageMaker, refer to Deploy large models on Amazon SageMaker using DJLServing and DeepSpeed model parallel inference.
After invocation, the asynchronous endpoint starts queueing our fine-tuning job. Each job runs through the following steps: prepare the images, perform Dreambooth and LoRA fine-tuning, and prepare the model artifacts. Let’s dive deeper into the fine-tuning process.
Prepare the images
As we mentioned earlier, the quality of input images directly impacts the quality of fine-tuned model. For the avatar use case, we want the model to focus on the facial features. Instead of requiring users to provide carefully curated images of exact size and content, we implement a preprocessing step using computer vision techniques to alleviate this burden. In the preprocessing step, we first use a face detection model to isolate the largest face in each image. Then we crop and pad the image to the required size of 512 x 512 pixels for our model. Finally, we segment the face from the background and add random background variations. This helps highlight the facial features, allowing our model to learn from the face itself rather than the background. The following images illustrate the three steps in this process.
 |
 |
 |
| Step 1: Face detection using computer vision | Step 2: Crop and pad the image to 512 x 512 pixels | Step 3 (Optional): Segment and add background variation |
Dreambooth and LoRA fine-tuning
For fine-tuning, we combined the techniques of Dreambooth and LoRA. Dreambooth allows you to personalize your Stable Diffusion model, embedding a subject into the model’s output domain using a unique identifier and expanding the model’s language vision dictionary. It uses a method called prior preservation to preserve the model’s semantic knowledge of the class of the subject, in this case a person, and use other objects in the class to improve the final image output. This is how Dreambooth can achieve high-quality results with just a few input images of the subject.
The following code snippet shows the inputs to our trainer.py class for our avatar solution. Notice we chose <<TOK>> as the unique identifier. This is purposely done to avoid picking a name that may already be in the model’s dictionary. If the name already exists, the model has to unlearn and then relearn the subject, which may lead to poor fine-tuning results. The subject class is set to “a photo of person”, which enables prior preservation by first generating photos of people to feed in as additional inputs during the fine-tuning process. This will help reduce overfitting as model tries to preserve the previous knowledge of a person using the prior preservation method.
A number of memory-saving options have been enabled in the configuration, including fp16, use_8bit_adam, and gradient accumulation. This reduces the memory footprint to under 12 GB, which allows for fine-tuning of up to two models concurrently on an ml.g5.2xlarge instance.
LoRA is an efficient fine-tuning technique for LLMs that freezes most of the weights and attaches a small adapter network to specific layers of the pre-trained LLM, allowing for faster training and optimized storage. For Stable Diffusion, the adapter is attached to the text encoder and U-Net components of the inference pipeline. The text encoder converts the input prompt to a latent space that is understood by the U-Net model, and the U-Net model uses the latent meaning to generate the image in the subsequent diffusion process. The output of the fine-tuning is just the text_encoder and U-Net adapter weights. At inference time, these weights can be reattached to the base Stable Diffusion model to reproduce the fine-tuning results.
The figures below are detail diagram of LoRA fine-tuning provided by original author: Cheng-Han Chiang, Yung-Sung Chuang, Hung-yi Lee, “AACL_2022_tutorial_PLMs,” 2022
 |
 |
By combining both methods, we were able to generate a personalized model while tuning an order-of-magnitude fewer parameters. This resulted in a much faster training time and reduced GPU utilization. Additionally, storage was optimized with the adapter weight being only 70 MB, compared to 6 GB for a full Stable Diffusion model, representing a 99% size reduction.
Prepare the model artifacts
After fine-tuning is complete, the postprocessing step will TAR the LoRA weights with the rest of the model serving files for NVIDIA Triton. We use a Python backend, which means the Triton config file and the Python script used for inference are required. Note that the Python script has to be named model.py. The final model TAR file should have the following file structure:
Host the fine-tuned models using SageMaker MMEs with GPU
After the models have been fine-tuned, we host the personalized Stable Diffusion models using a SageMaker MME. A SageMaker MME is a powerful deployment feature that allows hosting multiple models in a single container behind a single endpoint. It automatically manages traffic and routing to your models to optimize resource utilization, save costs, and minimize operational burden of managing thousands of endpoints. In our example, we run on GPU instances, and SageMaker MMEs support GPU using Triton Server. This allows you to run multiple models on a single GPU device and take advantage of accelerated compute. For more detail on how to host Stable Diffusion on SageMaker MMEs, refer to Create high-quality images with Stable Diffusion models and deploy them cost-efficiently with Amazon SageMaker.
For our example, we made additional optimization to load the fine-tuned models faster during cold start situations. This is possible because of LoRA’s adapter design. Because the base model weights and Conda environments are the same for all fine-tuned models, we can share these common resources by pre-loading them onto the hosting container. This leaves only the Triton config file, Python backend (model.py), and LoRA adaptor weights to be dynamically loaded from Amazon S3 after the first invocation. The following diagram provides a side-by-side comparison.

This significantly reduces the model TAR file from approximately 6 GB to 70 MB, and therefore is much faster to load and unpack. To do the preloading in our example, we created a utility Python backend model in models/model_setup. The script simply copies the base Stable Diffusion model and Conda environment from Amazon S3 to a common location to share across all the fine-tuned models. The following is the code snippet that performs the task:
Then each fine-tuned model will point to the shared location on the container. The Conda environment is referenced in the config.pbtxt.
The Stable Diffusion base model is loaded from the initialize() function of each model.py file. We then apply the personalized LoRA weights to the unet and text_encoder model to reproduce each fine-tuned model:
 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects. Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.from AWS Machine Learning Blog https://ift.tt/k1He4zd
No comments